구글 번역기가 개선됐다

구글이 인공지능을 이용해 번역기를 업그레이드했습니다. 기존 구글 번역기의 원리인 '어구 기반 기계 번역(Phrase Machine Translation)'은 단어 또는 어구를 하나하나 번역한 뒤 이를 퍼즐 맞추듯 조립해 뜻을 유추해야 했습니다
개선된 구글 번역기는 과거에 비해 성능이 나아졌다고 합니다. 구글 측 보도자료에 따르면 한국어, 영어, 중국어, 프랑스어, 독일어, 스페인어, 일본어, 터키어 등 8개 언어에 먼저 적용된 이번 업그레이드는 기존에 비해 오류를 55∼85%나 줄일 수 있게 됐다고 하는군요.
핵심은 머신 러닝 이용한 ‘신경망 번역’

이번 업그레이드에는 ‘신경망 번역(Neural Machine Translation)'이란 인공지능의 핵심 기술이 도입되었다고 합니다. '머신 러닝(기계 학습)'의 원리를 활용한 것이죠. MIT출신의 카네기 멜론 대학교의 교수 Tom M. Mitchell의 저서 <Machine Learning>에서는 기계 학습을 "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E"라고 정의하고 있습니다. 우리말로 풀어보자면 ‘어떠한 일처리(T)를 하는데 있어서 꾸준한 경험(E)을 통해서 수행 능력(P)을 높이는 것’ 정도가 되겠네요.
머신 러닝에서 ‘E’는 수많은 데이터에 해당합니다. 구글 번역기에서는 인간이 번역해 놓은 수많은 기존의 텍스트들이죠. 구글은 보도자료를 통해 “신경망 번역은 ‘크롤링(긁어 모으는)’을 통해 기존 번역 과정을 수집한다”며 “머신 러닝으로 생성된 '번역 인공지능'이 문장 전체를 이해하고 문장 Context(맥락)을 추론해 번역을 진행한다”고 설명하고 있습니다. 학습을 통해 똑똑해진 번역기가 번역 대상을 문장 단위로 이해해서 번역을 진행한다는 소리죠.
아직 완벽하진 않아

버락 투로프스키 구글 번역 프로덕트 매니지먼트 총괄은 보도자료를 통해 "신경망 번역 기술은 구글 번역이 지난 10년 동안 쌓아온 발전을 단 하루 만에 뛰어넘은 위대한 도약"이라고 자신들의 업적을 치켜세웠습니다.
극적인 표현은 좋지만 실제 성능을 체험 해보기 전에는 확신할 수 없겠죠. 기자가 직접 우리에게 익숙한 헌법 1조와 2조, ‘역사를 빛낸 100인의 위인’과 <IFL Science>에 실린 과학 기사 하나를 골라 직접 구글 번역기를 실행해 보았습니다.

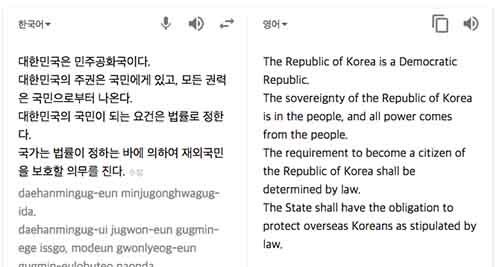

헌법 1조와 2조의 경우 많은 사람들이 번역기를 돌렸었는지 꽤나 정확한 번역을 해내는 모습이 놀랍습니다.
그래도 많이 왔다
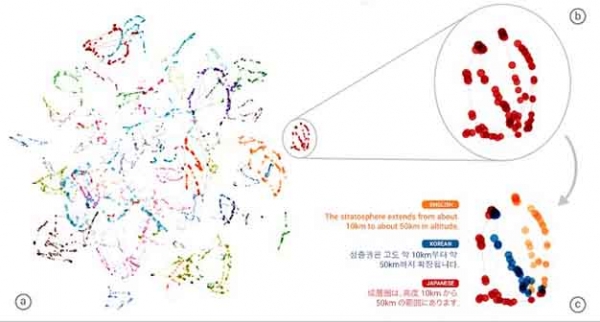
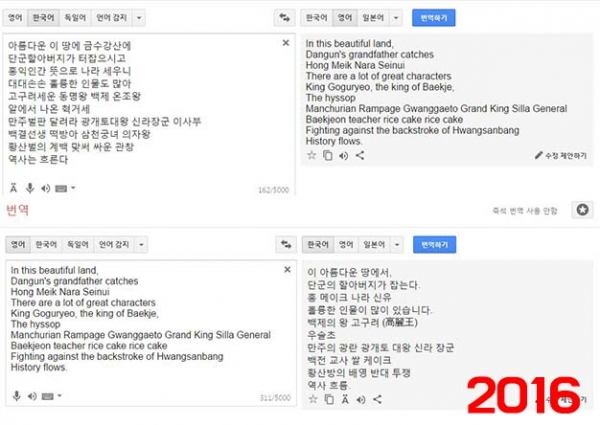
투로프스키 총괄은 "현재 신경망 번역의 가장 큰 과제는 문맥 속에 담긴 뜻을 해독하는 것이다. 문맥의 진정한 의미, 성별 등 고차원적인 부분을 아직 이해하지 못하고 있다. 이러한 문제를 해결하기 위해 번역 모델의 고도화 작업을 진행하고 있다"고 전했습니다.
구글은 모든 언어를 번역할 수 있는 보다 정교한 모델을 만드는 걸 목표로 하고 있다고 말합니다. 이를 위해서는 두 가지 숙제를 해결해야 합니다. 먼저 ‘103개에 달하는 언어를 어떻게 모두 학습시킬 것인가’와 ‘언어 사용자 수에 따라 차이가 있는 번역 데이터의 양을 어떻게 극복할 것인지’입니다.
구글은 이 숙제를 구조가 비슷한 언어끼리 묶는 방법으로 해결하겠다고 합니다. 예를 들어 한국어의 경우 언어 구조가 비슷한 일본어, 터키어와 번역 모델을 공유한다는 거죠.
103개에 이르는 언어를 각각의 상황 별로 모델을 구축하려면 총 1만 506개의 번역 모델을 만들어야 합니다. 하지만 유사한 언어끼리 번역 모델을 공유하면 번역 모델의 수를 크게 줄일 수 있을 것입니다. 또한 사용자가 많은 힌두어와 유사한 뱅갈어를 묶은 모델은 비교적 사용자가 적은 뱅갈어에게 보다 정확한 번역을 가능하게 할 것입니다..
외국어 공부 필요 없는 날?

성경은 인류의 언어가 제각각이 된 이유를 ‘하늘 끝에 닿고자 했던 바벨탑이 신의 노여움을 샀기 때문’이라고 설명합니다. 이 이야기 속에는 오랜 옛날부터 만국공용어에 대한 염원이 있었다는 것과, 동시에 만국공용어를 만드는 일이 신의 영역으로 여겨질 만큼 어렵다는 생각이 담겨있는 듯 합니다.
구글 뿐만 아니라 네이버와 삼성의 S번역기 등 다양한 회사들이 번역기 서비스를 개발하고 있습니다. 언젠가 번역가와 외국어 공부가 필요없어지는 날이 올까요?
모든 것을 알고 있다고 해서 ‘스카이넷’에 비유되기도 하는 구글도 10년에 걸친 연구가 ‘완벽하지 않은’ 결과물을 내놓은 것으로 미루어 볼 때 구글이 뛰어난 번역가 수준의 번역기를 내놓는데는 아직 시간이 좀 더 필요할 것으로 보입니다.
