
행렬 곱 연산은 선형 시스템과 그래픽 렌더링 등과 같은 응용뿐만 아니라 기계 학습 및 딥러닝(deep learning)과 같은 최신 응용에서도 기반이 되는 연산 중 하나입니다. 빅데이터 시대 들어 행렬의 크기는 폭발적으로 성장하면서 하나의 노드(node)에서는 행렬 곱 연산을 수행 할 수 없다고 합니다. 때문에 분산 행렬 곱 연산의 중요성이 더욱 강조되고 있죠.
하지만 최근 데이터 규모가 증가하며 기존 기술의 처리 능력도 한계에 다다랐다고 합니다. 특히 데이터 처리에 필수적인 곱셈 연산의 경우, 기존의 방식들로는 빅데이터와 같은 큰 규모의 데이터는 처리가 힘들다고 하는데요.
이에 DGIST의 연구진이 기존의 데이터 처리 기술과는 다른 방식으로 데이터를 분석하는 기술을 개발했다고 합니다. <ACM SIGMOD 2019>에 게재된 논문에 따르면 기존 기술보다 최대 14배 더 빠르며 100배 더 많은 데이터를 처리할 수 있는 'DistME(Distributed Matrix Engine) 기술'을 개발했다고 합니다.
분산 행렬 곱 연산 방법은?
분산 행렬 곱 연산은 하나의 노드에서 처리 할 수 없는 큰 행렬들을 작은 단위인 블록으로 분할하여 다수의 노드에서 행렬 곱 연산을 수행합니다. 분산 행렬 곱은 크게 세 단계로 구성됩니다.
- 행렬 분할 단계
- 로컬 행렬 곱 단계
- 행렬 누적 단계
행렬 곱 A×B=C 일 때, 행렬 분할 단계는 분산 행렬 곱을 수행하기 위해서 입력 행렬의 블록들을 노드들에게 분할 기법들에 따라서 분할하는 단계입니다. 로컬 행렬 곱 단계는 분할 된 블록들을 각 노드에서 행렬 곱 연산을 수행하는 단계죠. 그리고 마지막 행렬 누적 단계는 로컬 행렬 곱 단계에서 발생한 중간 블록들에 대해서 결과 행렬의 블록으로 만들기 위해서 누적 합 연산을 수행하는 단계입니다.
기존에는 SystemML, DMac, MatFast 등과 같은 기존의 시스템에서 사용되는 BMM, CPMM, RMM 등의 분산 행렬 곱 기술들을 사용했습니다. BMM은 하나의 행렬을 모든 노드들에게 복제하여 곱 연산을 수행합니다. CPMM은 입력 행렬들의 벡터들에 대한 outer product들에 대한 합을 이용해서 곱 연산을 수행하죠. 하지만 BMM과 CPMM은 각각 행렬 분할 단계와 행렬 누적 단계에서 네트워크 통신비용을 발생시키는데요. 하나의 노드는 행렬 곱에 사용되는 A, B, C들 중 하나의 모든 블록에 대한 공간이 필요하다는 단점이 있습니다.
RMM은 가능한 모든 블록들 간의 행렬 곱을 각각 수행하기 위해서 두 입력 행렬들을 분할 복제해 행렬 곱 연산을 수행합니다. 하지만 RMM의 경우 하나의 노드가 행렬의 모든 블록을 가질 필요는 없지만 BMM과 CPMM에 비해 더 많은 네트워크 비용이 발생하는 단점이 있습니다.
특히, BMM, CPMM, RMM의 분산 행렬 곱 기술들은 행렬 분할 단계에서 엄격한 기준 때문에 많은 네트워크 통신비용이 발생합니다. 또한, 기존의 시스템들은 행렬 곱 연산과 같이 계산 비용이 높은 연산들에 유리한 GPU와 같은 현대 하드웨어를 사용하지 않는다고 합니다.
연구진이 개발한 기술은?
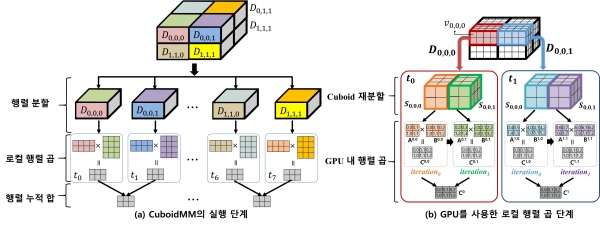
DGIST 정보통신융합전공 김민수 교수팀은 기존과 다른 행렬 곱셈 연산법을 고안했습니다. 'CuboidMM'이라 불리는 연산법은 정보를 3차원의 정육면체로 구성해 처리하는데요. 기존 곱셈 연산법들은 유동적인 적용이 불가능했지만, CuboidMM은 상황별 최적의 기법을 유연하게 적용해 연산을 수행할 수 있습니다. 추가적으로, 김민수 교수팀은 GPU(Grpahic Processing Unit)를 결합해 정보를 처리하는 법을 고안, 곱셈 연산 성능을 비약적으로 향상시켰다고 합니다.
CuboidMM 기술의 바탕으로 본연구진은 세계적으로 가장 많이 사용되는 Spark 프레임워크을 활용하여 대규모 행렬 계산 시스템인 DistME 시스템을 구현했습니다. DistME 기술은 CuboidMM을 GPU와 결합해 처리속도를 향상시킨 것인데요. DistME은 ScaLAPACK과 SystemML보다 각각 6.5배, 14배 더 빠른 데이터 분석 속도를 가졌으며 SystemML보다 100배 이상 더 큰 행렬 데이터 분석이 가능하다고 합니다.
DistME는 위 기술들을 모두 적절히 활용하여 기계 학습과 같은 질의 처리 시 수행되는 분산 행렬 곱 연산의 계산 성능을 매우 개선시켰으며 네트워크 I/O 비용을 상당히 줄이는데 성공했다고 합니다. 덕분에 동일한 질의 처리 환경에서 기존 시스템과 비교해 획기적으로 질의 처리 비용을 줄이면서 동시에 고속으로 질의를 처리 할 수 있다고 합니다.
앞으로의 전망

김민수 교수는 "최근 세계적으로 각광받는 기계학습 기술은 행렬형태의 빅데이터 분석 속도와 분석 처리 규모면에서 한계가 있었다"며 "이번에 개발한 정보처리 기술은 그 한계를 극복할 수 있는 기술로, 기계학습 뿐만 아니라 광범위한 과학기술 데이터 분석 응용에 유용하게 활용될 것으로 기대된다"고 말했습니다.
##참고자료##
